
 |
To get started with Microsoft Azure Databricks, log into your Azure portal. If you do not have an Azure subscription, create a free account before you begin. Create a resource in the Azure Portal, search for Azure Databricks, and click the link to get started. In the following blade enter a workspace name, select your subscription, resource group, location, and the pricing tier. Click create to submit the deployment for Azure Databricks. |
Once deployed Azure Databricks will be ready to use. Navigate to the service for links to the workspace and information on getting started. For this next step click Launch Workspace.

Single Sign On
Azure will redirect your browser to the Azure Databricks Portal and automatically sign you in using Azure Active Directory. User and access control can be set up under the Admin Console by the site administrator.

 |
PortalOn the left-hand side is the main menu for navigating around the Azure Databricks portal. The menu contains the Azure Databricks dashboard for quick access to common tasks. Next is the Home link to your user account and any Notebooks you have created. Workspaces hold all notebooks, libraries, and dashboards created by the team and allows importing notebooks from a file or URL. The Data menu will browse your folder directory of files or tables available. Clusters will let you create and manage Spark Clusters. Jobs are available in the 14-free day trial and once upgraded to Premium and allows for running notebooks on a schedule. |
Clusters
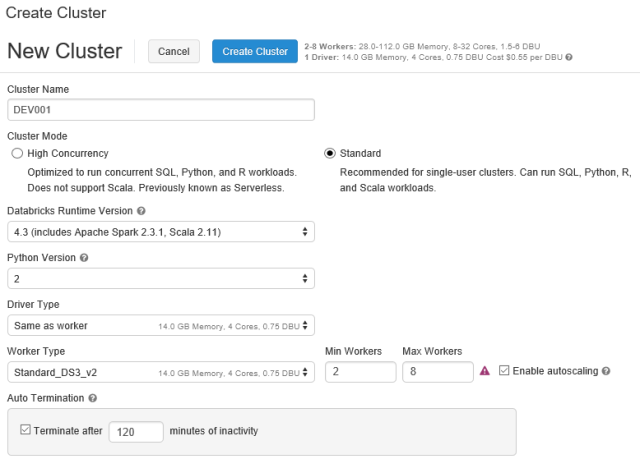
Creating a new cluster is easy with a single page to fill out. First give the cluster a name and select Standard Cluster Mode to get started. You can also switch the Databricks Runtime Version if you have specific Apache Spark or Scala version. Python can be switched from 2 to 3 if required. The Driver Type and Worker Types are virtual machines that will be spun up to make up the cluster. The minimum and maximum workers can be set. Please double check your subscription’s service limits as it may not have enough CPU cores available for autoscaling. The last option will set auto termination after a specific number of minutes to prevent overspending on your subscription. Click Create Cluster once ready to deploy the cluster to your subscription.
As of November 2018 the following are the supported version of Apache Spark. From Apache Spark 2.2.1 and Scala 2.10 up to Apache Spark 2.4.0 and Scala 2.11. This is very important for your code and libraries as functionality can be deprecated as new version are released. Please verify your code before running on your cluster.

Workspace
On the left-hand side is the main menu for navigating around the Azure Databricks portal. Click on workspace and the flyout menu will appear. Clicking the pin icon in the upper right-hand corner will keep it available. Drop down the menu under Workspace and hover over Create and there will be three options for Notebook, Library, and Folder.

Databricks Files System – DBFS
The data menu will allow browsing the Databricks File System and importing and exporting data. Click Add data to see the additional menu for uploading and browsing existing files. In Databricks a database is a collection of tables and a table is a collection of structured data. These are equivalent to Apache Spark DataFrames.
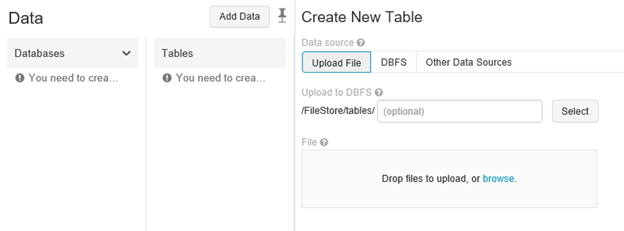
Raw data can also be uploaded in other formats such as CSV, JSON, TSV, or the following connector sources.

Libraries
This allows for loading packages into the Spark session and use them in Notebooks. There are four types of libraries that can be loaded and used in your Notebooks. The types are Java / Scala JAR files, Python Egg or PyPI, Maven Coordinate, and R Library.

Jobs
Jobs are only available during the 14-day free trial and the Premium version. With Jobs you can schedule a notebook to execute at any time. This could be for retraining a model after a new week of data has been collected. It can also be used to perform ETL operations for reporting.
